使用癌症蛋白质组学数据来确定候选基因治疗的目标
. DOI: 10.18632/oncotarget.28420")
一个新的研究视角题为“使用癌症蛋白质组学数据来确定候选基因治疗目标”已经发表在Oncotarget。
能够联系得到mass-spectrometry-based癌症蛋白质组学数据代表一个资源识别候选基因功能研究。在他们的新的研究视角,研究人员戴安娜Monsivais,悉尼大肠公园,沾光s Chandrashekar Sooryanarayana Varambally,和乍得j·克莱顿从贝勒医学院和伯明翰阿拉巴马大学最近的讨论他们的研究,他们调查了蛋白质组的肿瘤相关年级跨多个癌症类型和识别特定的蛋白质激酶功能影响子宫内膜癌细胞。
“这以前公布的研究提供了一个模板分子利用公共数据集来发现潜在的小说为癌症病人治疗的目标和方法,”研究人员解释。
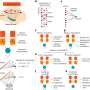
蛋白质组学分析数据结合相应multi-omics人类肿瘤和数据细胞系可以用不同的方法分析优先质问生物学感兴趣的基因。在成百上千的癌症细胞系CRISPR损失函数和药物敏感性得分很容易结合蛋白质数据预测基因功能的影响在板凳上进行实验。公共数据门户使癌症蛋白质组学数据更容易研究社区。药物发现平台可以屏幕数亿小分子抑制剂对于那些目标基因或感兴趣的途径。
“在这里,我们讨论一些可用的公共基因组和蛋白质组资源同时考虑如何将这些方法可以用于分子生物学见解或药物发现。我们还演示BAY1217389的抑制作用,TTK抑制剂最近测试的第一阶段临床试验治疗实体肿瘤,子宫癌症细胞系生存能力,”研究人员注意。
更多信息:戴安娜Monsivais et al,使用肿瘤蛋白质组学数据来识别基因治疗目标候选人,Oncotarget(2023)。DOI: 10.18632 / oncotarget.28420
期刊信息:
Oncotarget
期刊有限责任公司提供的影响
引用:使用癌症蛋白质组学数据,以确定候选基因治疗目标(2023年5月10日)2023年7月21日从//www.pyrotek-europe.com/news/2023-05-cancer-proteomics-gene-candidates-therapeutic.html获取
本文档版权。除了任何公平交易私人学习或研究的目的,没有书面许可,不得部分复制。内容只提供信息的目的。