特别报告列出了放射学人工智能处理的最佳实践的偏见
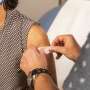
 Chest radiograph in a male patient with pneumonia. (B) Segmentation mask for the lung, generated using a deep learning model. (C) Chest radiograph is cropped based on the segmentation mask. If the cropped chest radiograph is fed to a subsequent classifier for detecting consolidations, the consolidation that is located behind the heart will be missed (arrow, A). This occurs because primary feature removal using the segmentation model was not valid and unnecessarily removed the portion of the lung located behind the heart. Credit: Radiological Society of North America")
越来越多地使用的人工智能(AI)在放射学,关键是尽量减少偏见在机器学习系统在实现他们的使用在实际临床场景,根据特殊的报告发表在《华尔街日报》放射学:人工智能。
报告,第一次在一个由三个部分组成的系列文章中,概述了次优实践中使用机器学习系统开发的数据处理阶段并提出策略来减轻。
“有12次优实践发生在数据处理阶段的机器学习系统,每一个都可以使系统偏差,”布拉德利·j·埃里克森说,医学博士博士,放射学和人工智能实验室主任教授梅奥诊所,明尼苏达州罗彻斯特市。“如果这些系统的偏差是否未被准确地量化,次优结果将接踵而至,限制人工智能应用程序的真实的场景。”
埃里克森博士说适当的数据处理的主题是获得更多的关注,然而指导方针的正确管理大数据稀缺。
“监管方面的挑战和转化差距仍然阻碍机器学习在实际的实现临床场景。然而,我们预计指数级增长在放射学人工智能系统加速清除这些障碍,”埃里克森博士说。“准备采用机器学习系统和临床的实现,这是很重要的一个方面,我们尽量减少偏见。”
在报告中,埃里克森博士和他的团队建议缓解策略的12次优实践发生在机器学习系统开发的四个数据处理步骤为每个数据处理步骤(3),包括:
- 数据集的数据collection-improper识别,单一来源的数据,不可靠的数据来源
- investigation-inadequate探索性数据分析,探索性数据分析,没有专业知识,未能观察到的实际数据
- 之间的数据splitting-leakage数据集,代表性的数据集,hyperparameters过度拟合
- 删除数据engineering-improper特性,特性重新调节不当,管理不善的丢失的数据
埃里克森博士说医疗数据经常不适合作为机器学习算法的输入。
“每一个步骤可能倾向于系统或随机的偏见,”他说。“这是开发人员的责任准确处理数据在数据采集等具有挑战性的场景,de-identification、注释、标签、和管理缺失的值。”
根据这份报告,仔细的规划数据收集应该包括深入审查临床和技术文献和协作与数据科学知识。
“机器学习多学科团队应该与两个数据成员或领导科学领域(临床)专业知识,”他说。
开发更多的异构数据集训练,埃里克森博士和他的合著者建议收集数据从多个机构从不同的地理位置,使用数据从不同的供应商和不同的时间,或包括公共数据集。
“创建一个健壮的机器学习系统需要研究者做侦探工作和寻找方法的数据可能会骗你,”他说。“你把数据训练模块之前,你必须分析它,确保它反映你的目标人群。AI不会为你做这些。”
埃里克森博士说,即使优秀的数据处理,机器学习系统仍然可以容易发生重大偏差。第二个和第三个的报道放射学:人工智能系列关注偏见,发生在模型开发和模型评估和报告阶段。
“近年来,机器学习在许多临床研究领域展示了其效用,从图像和重建假设检验提高诊断、预后和监控工具,”埃里克森博士说。“这一系列报告旨在识别错误的实践在机器学习的发展和减轻尽可能多的人。”
更多信息:Pouria Rouzrokh et al,减少偏见在放射学机器学习:1。数据处理,放射学:人工智能(2022)。DOI: 10.1148 / ryai.210290