研究人员发现大脑区域集成演讲的节奏

杜克大学和麻省理工学院的科学家发现大脑的一个区域,这个区域敏感言论的时机,口语的一个至关重要的元素。
时间关系到人类语言的结构。例如,音素是最短,最基本单元的言论和去年平均30到60毫秒。相比之下,音节需要更长时间:200 - 300毫秒。大部分单词是更长的时间。
为了理解演讲,大脑需要以某种方式整合这个快速发展的信息。
听觉系统,就像其他感官系统,可能需要快捷方式应对信息的冲击,例如,抽样信息块相似的长度平均的辅音字母或音节,说研究的合著者Tobias Overath,杜克大学的心理学和神经科学的助理研究教授。麻省理工学院的其他通讯作者是杰克·麦克德莫特。
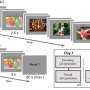
在一项研究中出现在《华尔街日报》5月18日自然神经科学,Overath和他的合作者外国演讲的录音切成短块从30到960毫秒的长度,然后重新组装件使用一种新颖的算法来创建新的声音,作者称之为“演讲棉被”。
越短的演讲棉被,破坏越大是演讲的原始结构。
实时测量神经元的活动,扮演的科学家演讲被子研究参与者,同时扫描他们的大脑在功能性磁共振成像机器。研究小组推测,语音处理相关的脑区会显示更大的言论反应被子长段组成。
事实上,大脑的一个区域称为颞上沟(STS)成为高度活跃在480 - 960毫秒棉被与30-millisecond棉被。
相比之下,大脑的其他区域参与处理声音并没有改变他们的反应结果的差异在被子的声音。
“这是非常令人兴奋的。我们知道我们到什么东西,“Overath说,他是一个杜克大学脑科学研究所的成员
颞上沟是听觉和其他感官信息集成。但是没有人表明,STS对时间很敏感结构的演讲。
排除其他解释STS的激活,研究人员测试了许多控制言论听起来他们创造的模仿。的一个合成听起来他们创造了分享演讲的频率,但缺乏它的节奏。另一个删除了所有演讲的音高。第三个使用环境的声音。
他们缝制这些控制刺激,砍在30 -或960毫秒,缝合一起回去,之前玩他们的参与者。STS似乎并不对绗缝操作时应用这些控制声音。
“我们真的要竭尽全力确保我们看到在STS的效应是由于speech-specific处理而不是由于一些其他解释,例如,音高的声音或这是一个自然的声音,而不是一些电脑合成的声音,“Overath说。
该集团计划在STS研究的响应是否对外国类似演讲比英语语音学上完全不同,比如普通话,或者被子的熟悉的语言理解和有意义的。他们熟悉的演讲可能会看到更强的激活大脑的左侧,在处理语言被认为是主导。
更多信息:speech-specific颞皮质分析结构揭示了反应声音棉被,自然神经科学,DOI: 10.1038 / nn.4021