科学家们生成了与癌症相关的基因变异的最大数据集
根据发表在《柳叶刀》上的一项研究,美国国家癌症研究所(NCI)的科学家们已经生成了一套癌症特异性遗传变异的数据集,并将这些数据提供给研究界癌症研究是美国癌症研究协会的一本杂志。
这将有助于癌症研究人员更好地理解药物反应以及对癌症治疗的抵抗力。
“迄今为止,这是全球最大的数据库,包含60亿个数据点,将药物与整个基因组变体联系起来人类基因组来自9个组织的细胞系,包括乳房、卵巢、前列腺、结肠、肺、肾、脑、血液和皮肤,”马里兰州贝塞斯达NCI分子药理学实验室主任、医学博士伊夫·波米耶(Yves Pommier)在接受采访时说。“我们将这个数据集公开给更大的社区使用和分析。
Pommier补充说:“随着越来越多的癌症相关基因畸变被发现,向研究人员开放这一广泛的数据集将扩大我们对肿瘤发生(正常细胞转化为癌症的过程)的知识和理解。”“这来得正是时候,因为基因组医学正在成为现实,我非常希望这一有价值的信息将改变我们在精准医疗中使用药物的方式。”
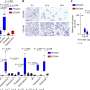
Pommier及其同事对NCI-60进行了全外显子组测序人类癌症细胞系面板,这是60个人类癌细胞系的集合,并生成了癌症特异性遗传变异的全面列表。研究人员进行的初步研究表明,广泛的数据集有可能极大地增强对特定癌症相关遗传变异和药物反应之间关系的理解,这将加速药物开发进程。
NCI-60人类癌细胞系面板被癌症研究人员广泛用于发现新的抗肿瘤细胞抗癌药物.为了进行全外显子组测序,Pommier和他的NCI团队从60种不同的细胞系中提取DNA,这些细胞系代表肺癌、结肠癌、脑癌、卵巢癌、乳腺癌、前列腺癌和肾癌,以及白血病和黑色素瘤,并对整个人类基因组的遗传编码变体进行了编组。确定的遗传变异有两种类型:I型变异对应于在正常人群中发现的变异,II型变异是癌症特异性的。
然后,研究人员使用超级学习者算法来预测携带II型变异的细胞对FDA批准的103种抗癌药物和另外207种研究性新药的敏感性。他们能够研究关键癌症相关基因和临床相关抗癌药物之间的相关性,并预测结果。
Pommier说,这项研究中产生的数据为确定药物耐药性的新决定因素和机制提供了手段,并为靶向基因组缺陷和克服获得性耐药性提供了机会。为了实现这一点,研究人员正在通过两个数据库门户,即CellMiner数据库和Ingenuity系统数据库,向所有研究人员提供这些数据。