2013年6月24日功能
的核心问题:识别复发基因组区域来确定肿瘤的发展史
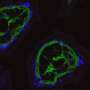
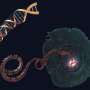
 cores. Copyright © PNAS, doi:10.1073/pnas.1306909110")
(bob游戏医疗Xpress)分析从生物全基因组数据,组织或细胞生成的列表基因组的间隔——连续结构基因组序列,如染色体。间隔的意思取决于它的基因组上下文,并且可以确定一个地区的癌症相关DNA拷贝数变化(改变基因组的DNA,导致细胞异常数量的一个或多个副本的DNA片段)。最近,科学家在冷泉港实验室设计了计算生物学方法核心(重复事件的核心),解释了全基因组数据的一小部分核心——也就是说,复发性间隔,为研究肿瘤亚种群和癌症类型拷贝数畸变。
教授亚历山大•Krasnitz讨论研究,他教授迈克尔•wigle研究生果太阳,安德鲁斯博士和彼得。“构建我们的方法面临的主要挑战是找到合适的形式,我们称之为解释、“Krasnitz告诉医疗Xprebob游戏ss。研究者的方法利用一个核心来“解释”观察间隔事件通过分配的几何关系。”使用的一些形式我们提出和确定复发的广义和狭义的基因组区域,“Krasnitz补充道,“让工作方法在大范围的大小基因组区域从整个小于单个基因染色体。"
Krasnitz指出,核心是实现为一个组合优化过程,包括统计测试设计必须非常小心。“在任何研究,”他指出,“统计数据往往是最危险的部分。弄错一个方向,你就会错过重要的发现,但错在相反的方向,你会做假,不能复制的发现。我们花了很大的努力找到中间立场。”
展示的第一步核心解释数据的能力与不同长度的核心与合成数据检查系统性能。“生成人工数据算法应该提供的答案是提前知道是标准的实践领域的数据分析,“Krasnitz评论。“核心通过了这一考验我们的满意度。”The researchers then provided two demonstrations of CORE's utility with actual data. "By this we mean that on the one hand, CORE uncovers the genealogy of cells in a tumor, and on the other, can identify characteristic patterns of copy number variation in breast cancer."

科学家们运用他们的方法的方法之一是确定肿瘤细胞人口发展史(也就是说,细胞谱系的历史他们通过时间改变)。为此,他们应用DNA拷贝数的集合的核心配置文件从单个细胞的肿瘤。现在可以使用“这些单细胞基因组资料由于高度创新实验工作的迈克尔•wigle)和他的团队“Krasnitz指出。
Krasnitz继续说道,“而且,这是至关重要的,以确定肿瘤细胞中发现彼此相关的血统。”For example, he illustrates, they sometimes find that cells closely related to each other reside far apart in the tumor mass, which points to their ability to migrate rather than stay anchored as a healthy epithelial cell would. "However," he cautions, "our reconstructed genealogy must be accurate if we were to make such a claim."
功能独立的种群在内核中发现。识别这些特性提出了一个统计的挑战。”我们是什么意思,“Krasnitz所示,“当我们说功能一个存在于细胞的基因组?毕竟,核心是扩展的对象,而不是单个字母的基因组。如果一个细胞基因组区域中发现类似于核心但不相同吗?我还能宣称的核心基因组中存在细胞?有很多不同的答案,这取决于程度的相似性要求。结果,研究人员必须测试许多假设,分析复杂数据时这是常有的事。为了缓解这个问题,他补充道,他们借从机器学习技术。
另一个主要困难是应用比较基因组杂交的核心数据从一个大的肿瘤样本,以便于确定地区乳腺癌的复发性拷贝数偏差。Krasnitz,“每个肿瘤分析有关,“我们不得不处理基因数据平均值数以百万计的肿瘤细胞。这个平均削弱我们的检测能力DNA复制数量变化出现在一些,但并不是所有的细胞。我们必须克服这个困难之前我们可以应用核心。”

Krasnitz解释说,在这种情况下,他们能够检测非常狭窄的核心与跨整个染色体的核心武器。此外,一些狭窄的核心指向已知重要的乳腺癌基因,比如ERBB2,赫赛汀®(曲妥珠单抗)的目标。”这表明其他狭窄的核心应该为存在潜在的药物靶点,探讨“Krasnitz指出。
尽管一系列重大挑战,Krasnitz看到一个关键论文的创新概念的压倒一切的价值:解释。“正如一位评论家指出,“他说,”最大化的解释是一个替代可能性最大化作为实验数据建模方法。我们希望这个概念能够扎根在其他领域,不仅在基因组学”。
例如,Krasnitz指出,在网络分析中,这些观点可以用来找到一组最优的中心,这样网络中的每个节点连接到至少一个中心。问题核心的另一个例子可能是有用的,他补充说,是如何雇佣一个固定数量的专家从一个庞大的候选人,以最大化他们的集体知识。
这项研究的一个有趣的方面是,某些协会措施比其他人更有利的算法复杂度。“这是一个很好的实例如何相互联系的现代科学,“观察Krasnitz。“在早期阶段的工作我们感兴趣的一个特定形式的解释。我们第一次试图通过蛮力来解决这个问题——也就是说,通过详尽的搜索中最好的一个巨大的数量的可能的解决方案,但很快跑出计算能力。我们很惊奇地发现一个非常优雅的解决类似的问题早在1991年,两名以色列数学家在运筹学领域工作,雷米尔Hassin和阿里,他表明,在这种特殊情况下的复杂性问题可以大大减少1。不幸的是,我们后来理解——这种形式的解释,而有利的计算,不是理想的基因组学的问题。”
前进,科学家们正在探索其他形式的解释,能够更好地考虑随机性出现在基因组数据。“首先,我们计划发布核心作为公共软件使其由其他研究人员使用,“Krasnitz指出。“内部,我们有两个正在进行的研究——一个使用核作为癌症标记药物治疗的反应性,而另一个使用核心改善分子诊断的癌症患者。”
进一步探索
相关的
1改善复杂边界位置问题实线,行动研究快报10 (1991),395 - 402,0167 - 6377 . doi: 10.1016 / (91) 90041 - m(PDF)
医学Xpresbob游戏s©2013。保留所有权利。